{kind=link}
Search for mileage awards on multiple airlines
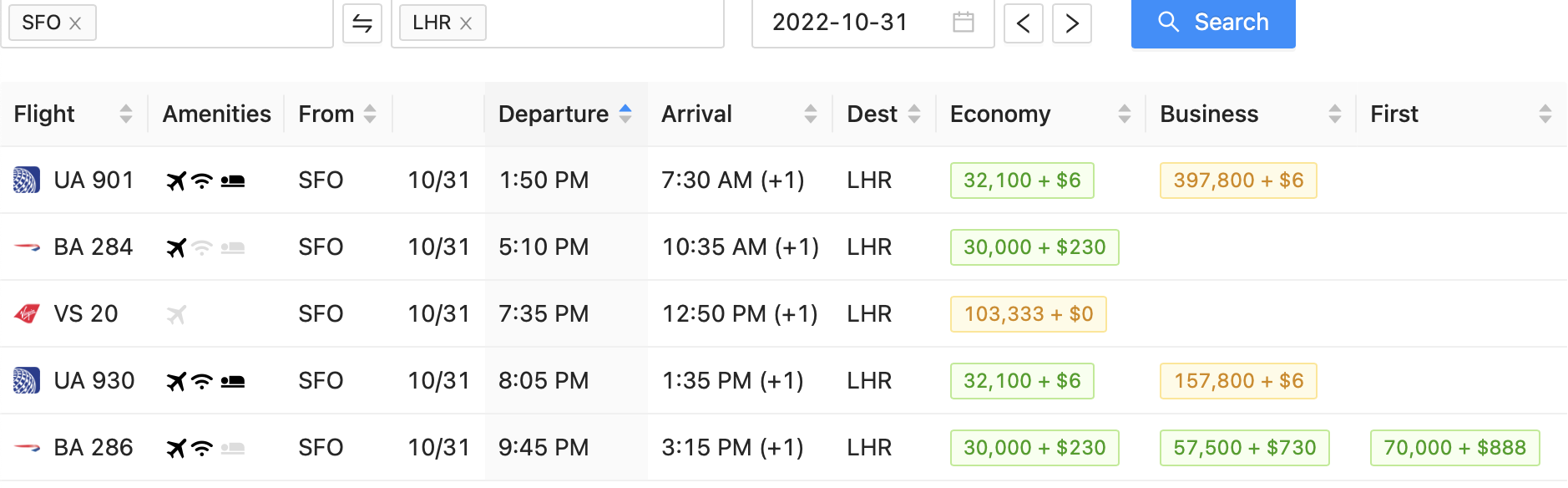
Generally, finding flights to spend points/miles is incredibly difficult due to the seemingly random availability of award flights. Though it's most practical to manually search just one or two airlines' websites, there are often many more options actually available, and some quite a bit cheaper and better! Automation is therefore necessary to do all the permutations of airlines/dates/routes/classes so we can be sure we're getting the best deal. Additionally, the websites for these airlines change a lot, so keeping things opensource is important.
AwardWiz uses AWS Lambda functions to spin off a bunch of scrapers for the different award programs for a given airline routing. These scrapers are in the scrapers directory. The cloud providers can be found in the cloud-providers (though only AWS is supported for now). The frontend static HTML/Javascript is where all the logic and signalling as to which lambdas to run resides.
As there is no server-side "backend", this entire project is just a static website which takes heavy advantage of CORS calls to the user's cloud provider to create the functions necessary. No asset pipelines or frameworks are used, and when external libraries are, they're included with <script> tags. Using cloud functions is quite beneficial in that you could theoretically spin up hundreds all at once in minimal time/cost. Currently the way the functions work is that when run, they will download the node modules first on the lambda side, and then continue execution. Since cloud platforms cache these environments, the npm install process isnt as laborous the second time around.
The point of this setup is so that anybody can host this scaleable service just about anywhere, and users can hook up their own cloud at runtime so costs go straight to the end-user. For convenience, you can try it out at https://awardwiz.com -- that's always master from the Github code being pulled live via Netlify.
- Git clone this repo
- Start a local server with this code using
python -m SimpleHTTPServer - Open a browser at http://localhost:8000/ and open the Dev Console
- Fill out the requested info and click the "prep" button
- If that succeeds, change the search params and click the "search" button to your heart's content!
Basically you just edit the HTML and Javascript files directly, but consider running yarn locally to make sure stuff like eslint is installed and working. Optionally running yarn test will run tests locally, which is also a great way of debugging via a real chrome for those pesky airline websites. TODO: instructions how to do this.
To debug the main code with VSCode, use the Launch Chrome against localhost option along with either using the python one-liner above, or using something like the "Live Server" extension.
To debug or create scrapers with VSCode, it's a bit more complicated. First, make sure you ran yarn to install Chromium and Puppeteer. There's a convenience script in scrapers/debug.js which basically hits the same thing the cloud function would. This can be run from VSCode with debugger attached via the Debug scraper config. When running a scraper locally Chromium won't be headless, plus stuff like the dev tools will be automatically opened. If using Debug scraper, make sure to create a .env file with the parameters in scrapers/debug.js.
Please file PRs for updates to this document if you feel like others could benefit from something you figured out while setting up your dev environment!
Create a new file in the scrapers/ directory. Here's the initial template to get started:
/**
* @param {import("puppeteer").Page} page
* @param {SearchQuery} input
*/
exports.scraperMain = async(page, input) => {
console.log("Going to search page...")
await page.goto("https://www.airline.com")
/** @type {SearchResult[]} */
const flights = []
return {searchResults: flights}
}Put a breakpoint on that return line. Then go to the scrapers/debug.js file and change the parameters to be for your new scraper. Start the Debug scraper launcher and wait for the breakpoint to get hit. Once it does, you're in the right context and figure out the commands you'll need to issue Puppeteer to properly scrape what you need.
Some tips about scraping results from sites:
- Take good account of the different ways to search, some are easier to automate than others (front page of the airline vs an "advanced" search vs a mobile view vs a logged-in view on either of these).
- Consider the different ways it can return results. Aside from the suggestions on the previous point, look for options like time-bars which may expose more flight info without the need for more requests.
- Sometimes you can just intercept the results json as it comes, that way you don't need to even scrape. United and Aeroplan work this way.
- add GCP, Azure, Apify and other cloud function providers
- auto pull in points from AwardWallet
- auto generate routes here instead of using the airlines (since we're smarter)
- auto select airlines based on AwardHacker data
- suggest which airlines to get more miles onto (i.e. "you could have saved X miles if you had these kinds of miles")
- auto calculate cost savings
- Puppeteer docs: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
- Typescript JSDoc notation: https://www.typescriptlang.org/docs/handbook/type-checking-javascript-files.html