This repo contains the official PyTorch implementation of the NeurIPS'22 paper
Training Scale-Invariant Neural Networks on the Sphere Can Happen in Three Regimes
Maxim Kodryan*,
Ekaterina Lobacheva*,
Maksim Nakhodnov*,
Dmitry Vetrov
arXiv / openreview / short poster video / long talk (in Russian) / bibtex
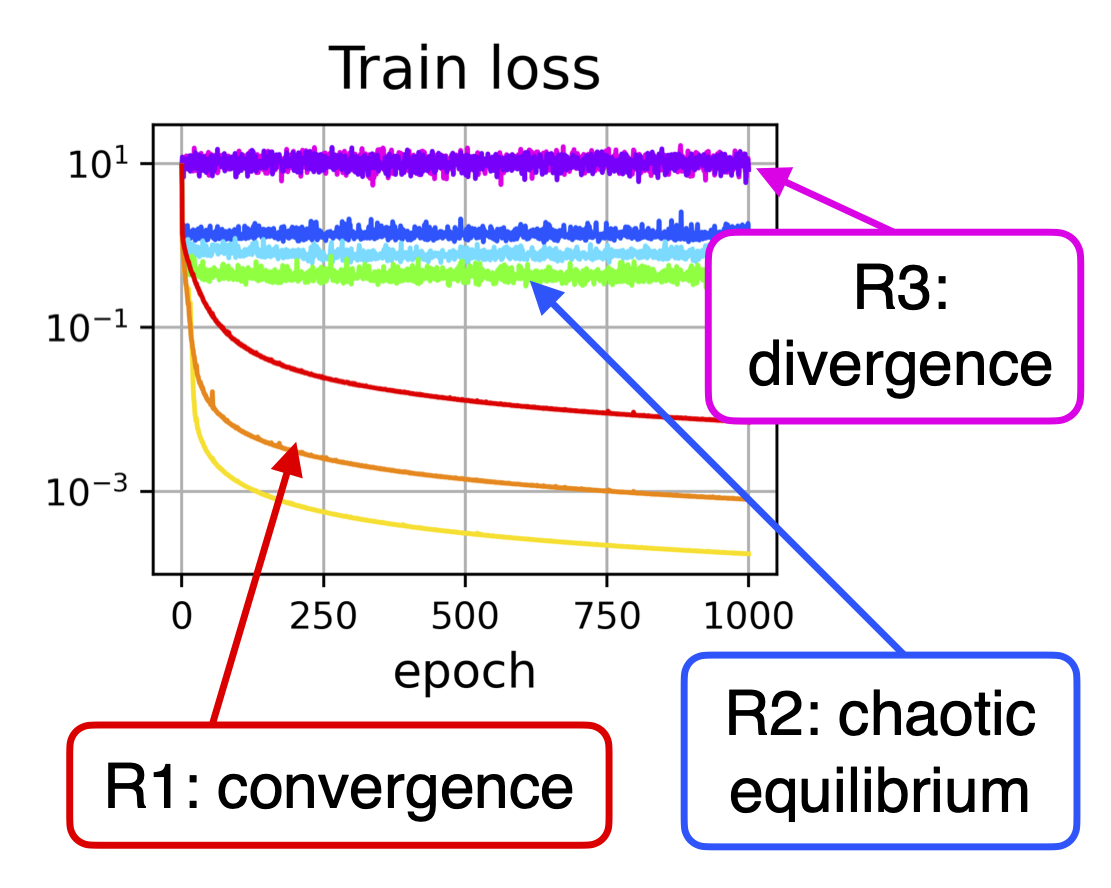 A fundamental property of deep learning normalization techniques, such as batch
normalization, is making the pre-normalization parameters scale invariant. The
intrinsic domain of such parameters is the unit sphere, and therefore their gradient
optimization dynamics can be represented via spherical optimization with varying
effective learning rate (ELR), which was studied previously. However, the varying
ELR may obscure certain characteristics of the intrinsic loss landscape structure. In
this work, we investigate the properties of training scale-invariant neural networks
directly on the sphere using a fixed ELR. We discover three regimes of such training
depending on the ELR value: convergence, chaotic equilibrium, and divergence.
We study these regimes in detail both on a theoretical examination of a toy example
and on a thorough empirical analysis of real scale-invariant deep learning models.
Each regime has unique features and reflects specific properties of the intrinsic
loss landscape, some of which have strong parallels with previous research on
both regular and scale-invariant neural networks training. Finally, we demonstrate
how the discovered regimes are reflected in conventional training of normalized
networks and how they can be leveraged to achieve better optima.
A fundamental property of deep learning normalization techniques, such as batch
normalization, is making the pre-normalization parameters scale invariant. The
intrinsic domain of such parameters is the unit sphere, and therefore their gradient
optimization dynamics can be represented via spherical optimization with varying
effective learning rate (ELR), which was studied previously. However, the varying
ELR may obscure certain characteristics of the intrinsic loss landscape structure. In
this work, we investigate the properties of training scale-invariant neural networks
directly on the sphere using a fixed ELR. We discover three regimes of such training
depending on the ELR value: convergence, chaotic equilibrium, and divergence.
We study these regimes in detail both on a theoretical examination of a toy example
and on a thorough empirical analysis of real scale-invariant deep learning models.
Each regime has unique features and reflects specific properties of the intrinsic
loss landscape, some of which have strong parallels with previous research on
both regular and scale-invariant neural networks training. Finally, we demonstrate
how the discovered regimes are reflected in conventional training of normalized
networks and how they can be leveraged to achieve better optima.
Environment
conda env create -f SI_regimes_env.yml
Example usage
To obtain one of the lines in Figure 1 in the paper:
- Run script run_train_and_test.py to train and compute metrics (in the presented form, it trains a scale-invariant ConvNet on CIFAR-10 using SGD on the sphere with ELR 1e-3).
- Use notebook Plots.ipynb to look at the results.
Main parameters
To replicate other results from the paper, vary the parameters in run_train_and_test.py:
- dataset: CIFAR10 or CIFAR100
- to train fully scale-invariant networks use models ConvNetSI/ResNet18SI, fix_noninvlr = 0.0 (learning rate for not scale invariant parameters), and initscale = 10. (norm of the last layer weight matrix)
- to train all network parameters use models ConvNetSIAf/ResNet18SIAf, fix_noninvlr = -1 and initscale = -1
- to train networks on the sphere use fix_elr = 'fix_elr' and some positive elr value
- to train network in the whole parameter space use fix_elr = 'fix_lr' and some positive lr_init value (+ we use weight decay wd in this setup)
- to turn on the momentum use a non-zero value for it in params
- to turn on data augmentation delete the noaug option from add_params
Parts of this code are based on the following repositories:
- On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay. Ekaterina Lobacheva, Maxim Kodryan, Nadezhda Chirkova, Andrey Malinin, and Dmitry Vetrov.
- Rethinking Parameter Counting: Effective Dimensionality Revisted. Wesley Maddox, Gregory Benton, and Andrew Gordon Wilson.
If you found this code useful, please cite our paper
@inproceedings{kodryan2022regimes,
title={Training Scale-Invariant Neural Networks on the Sphere Can Happen in Three Regimes},
author={Maxim Kodryan and Ekaterina Lobacheva and Maksim Nakhodnov and Dmitry Vetrov},
booktitle={Advances in Neural Information Processing Systems},
year={2022},
url={https://openreview.net/forum?id=edffTbw0Sws}
}