News 🔥
- [2025/02] We release a new version of PEARL paper. link
- [2025/01] PEARL is accepted to ICLR 2025
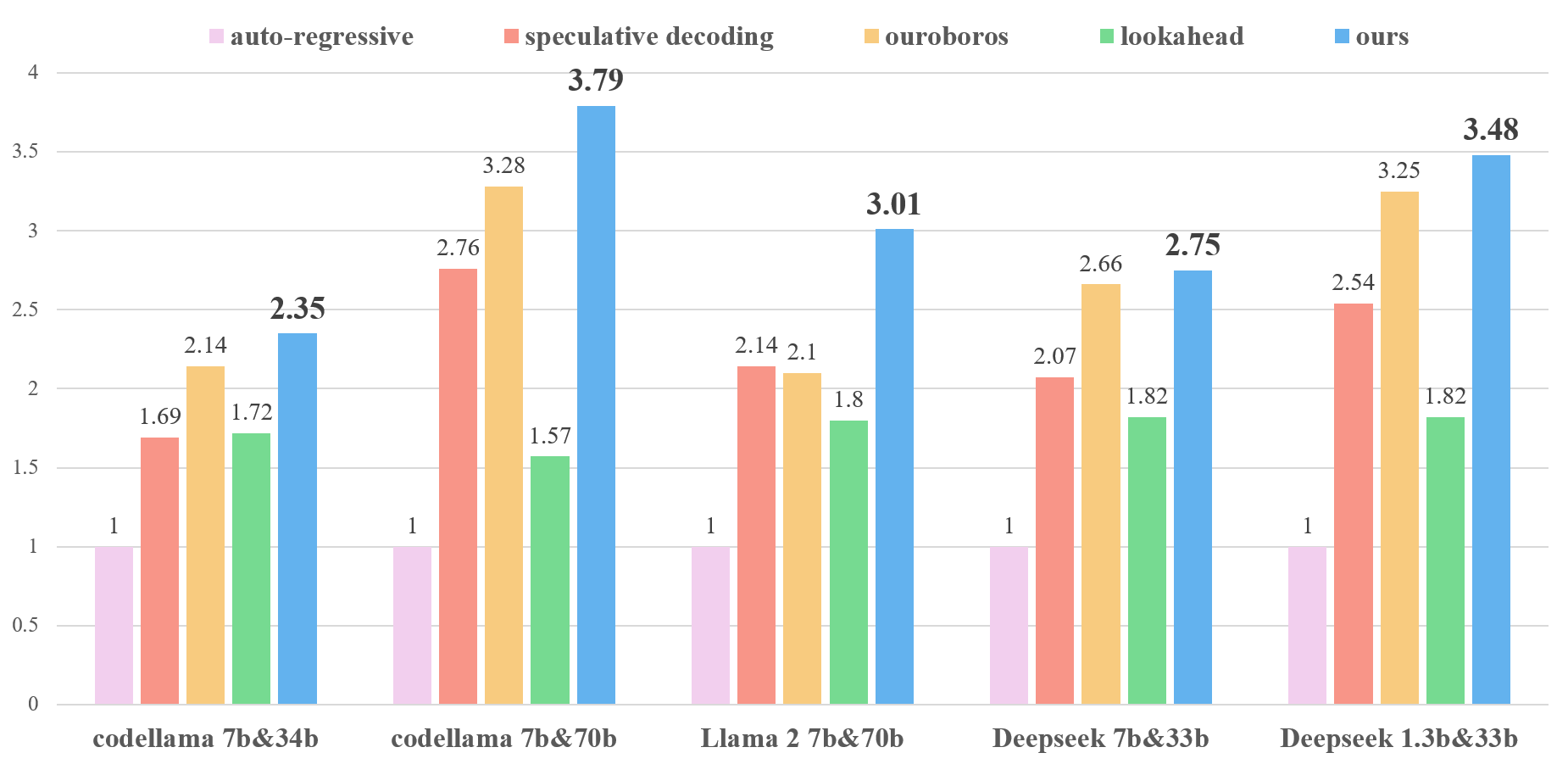
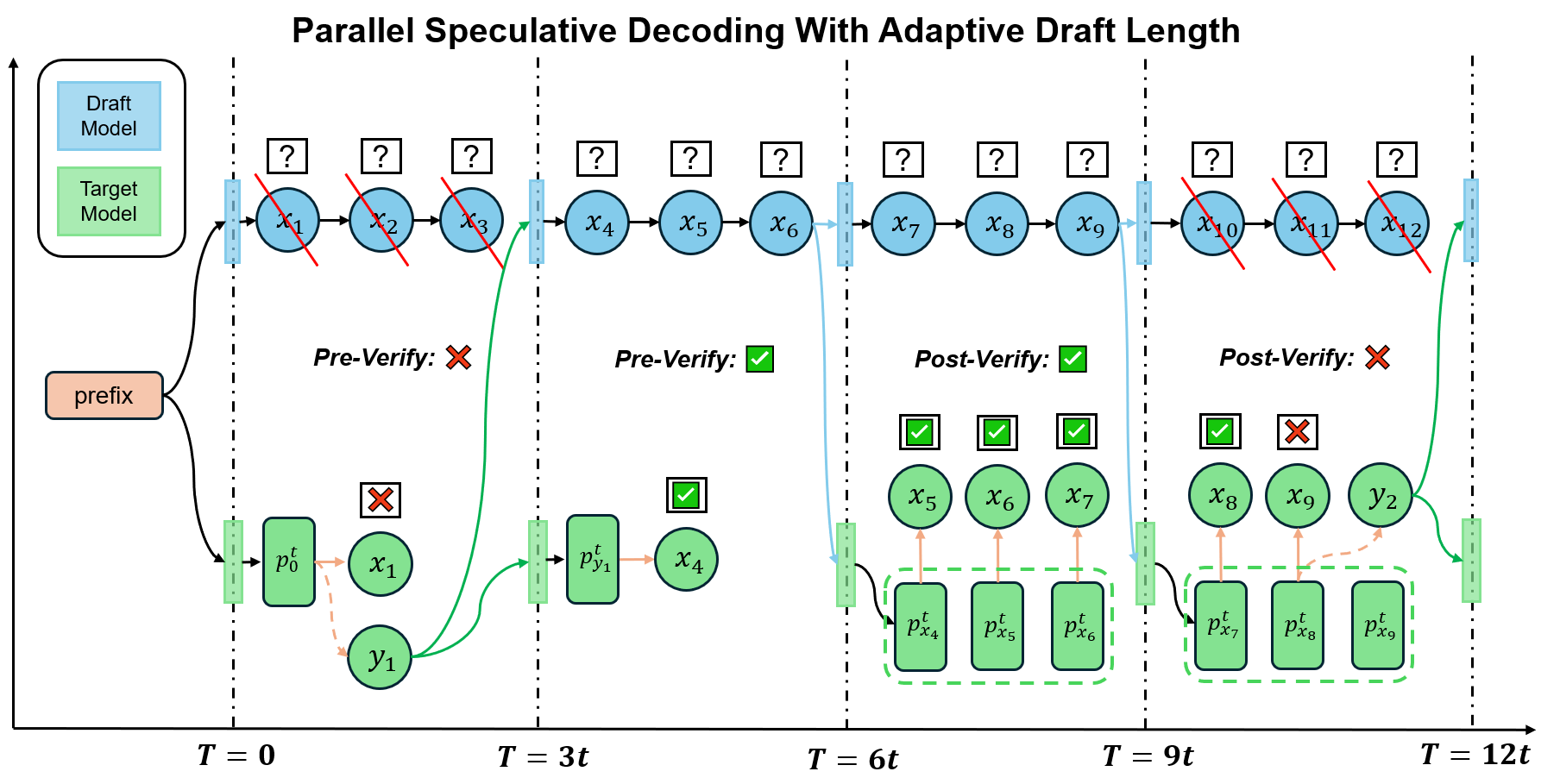
TL; DR: we introduce PEARL (Parallel spEculative decoding with Adaptive dRaft Length) to further reduce the inference latency of Large Language Models (LLMs). PEARL is a parallel inference framework based on speculative decoding which utilizes pre-verify and post-verify to achieve adaptive draft length. In summary, our PEARL is:

Figure 2. Generation speed of Llama 2 chat 70B using PEARL and auto-regressive decoding, with inference conducted on A100 80G GPUs at bf16 precision.
Our PEARL framework consists of a draft model, a target model and two strategies to decode tokens. The two strategies are switched according to the verification results in the last decoding step.
Follow the instructions below to prepare for reproducing the results in the paper.
- experimental environment:
sh install.shwill install the necessary packages in the project. - code changes: changes the code
src/util.pyline 31-38 and line 49, to fill in your model paths and data paths.
All the running scripts, including scripts for auto-regress decoding, vanilla speculative decoding, parallel speculative decoding, comparison, ablation studies and case studies. These scripts can be directly executed for reproduction.
sh scripts/run_para_sd.shYou can try this code with a simple command:
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes 2 benchmark/eval_humaneval.py --eval_mode para_sd --gamma 5 -n 1 -e H_PSD_codellama_7_70b --draft_model codellama-7b --target_model codellama-70b --max_tokens 1024 --temp 0We have provided a suggested web interface, which you can use by running the following command.
Currently, This
applications.pyis just a test demo for visualization, and there are many bugs in the ugly code. We strongly recommend users to refer tobenchmark/eval_mt_bench.py. Running this demo with UI MUST enable the buttonUse PEARLandHighlight the tokens generated by PEARL.
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes 2 applications.py --eval_mode para_sd --gamma 5 -n 1 -e applications --draft_model codellama-7b --target_model codellama-70b --max_tokens 1024 --temp 0- AttributeError: 'list' object has no attribute 'get_seq_length'.
In latest transformers (version >= 4.49.0), all the past_key_values are class of DynamicCache instead of tuple. Hence you should change the error line of code from past_key_values[0][0].shape[2] to past_key_values.get_seq_length(). We have fixed some bugs within the code. If you find any bug, feel free to raise an issue.
- Unexpected generations, such as meaningless text.
This issue may be directly caused due to precision overflow. You can add .to(torch.float32) to solve this issue. (Such as Line 187 of src/engine.py)
- Performance on Qwen Series Model.
We briefly test the speedup of PEARL based on Qwen 2.5 7b & 72b, and find that PEARL can achieve over 2.5$\times$ speedup as well. Any additional experiment is warmly welcomed!
- Other details.
Please refer to the 知乎 blog.
If you find our work useful your research, please cite our paper:
@inproceedings{
liu2025pearl,
title={{PEARL}: Parallel Speculative Decoding with Adaptive Draft Length},
author={Tianyu Liu and Yun Li and Qitan Lv and Kai Liu and Jianchen Zhu and Winston Hu and Xiao Sun},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=QOXrVMiHGK}
}
@misc{liu2025pearlparallelspeculativedecoding,
title={PEARL: Parallel Speculative Decoding with Adaptive Draft Length},
author={Tianyu Liu and Yun Li and Qitan Lv and Kai Liu and Jianchen Zhu and Winston Hu and Xiao Sun},
year={2025},
eprint={2408.11850},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.11850},
}