Update fastspeech2 model card #37377
Conversation
|
Hi 👋, thank you for opening this pull request! The pull request is converted to draft by default. The CI will be paused while the PR is in draft mode. When it is ready for review, please click the |
|
cc @stevhliu |
| #### Convolution Module | ||
| 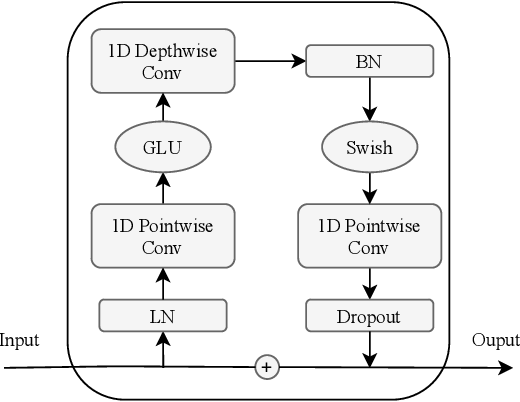 | ||
| <hfoptions id="usage"> | ||
| <hfoption id="Pipeline"> |
There was a problem hiding this comment.
@eustlb, would you mind taking a look at why the code is failing here? It returns a AttributeError: 'FastSpeech2ConformerConfig' object has no attribute 'model_config' error which seems to be available here. Thanks!
# pip install -U -q g2p-en
import torch
import soundfile as sf
from transformers import pipeline, FastSpeech2ConformerHifiGan
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(task="text-to-audio", model="espnet/fastspeech2_conformer", vocoder=vocoder, device=0, torch_dtype=torch.float16)
speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])There was a problem hiding this comment.
Nice catch, let's simply modify modeling_audio.py's MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING_NAMES
MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING_NAMES = OrderedDict(
[
# Model for Text-To-Waveform mapping
("bark", "BarkModel"),
("csm", "CsmForConditionalGeneration"),
("fastspeech2_conformer", "FastSpeech2ConformerModel"),
("fastspeech2_conformer_with_hifigan", "FastSpeech2ConformerWithHifiGan"),
("musicgen", "MusicgenForConditionalGeneration"),
("musicgen_melody", "MusicgenMelodyForConditionalGeneration"),
("qwen2_5_omni", "Qwen2_5OmniForConditionalGeneration"),
("seamless_m4t", "SeamlessM4TForTextToSpeech"),
("seamless_m4t_v2", "SeamlessM4Tv2ForTextToSpeech"),
("vits", "VitsModel"),
]
)|
|
||
| ```python | ||
| </hfoption> | ||
| <hfoption id="AutoModel"> |
There was a problem hiding this comment.
Let's use the combined version so its easier:
# pip install -U -q g2p-en
import soundfile as sf
import torch
from transformers import AutoTokenizer, FastSpeech2ConformerWithHifiGan
tokenizer = AutoTokenizer.from_pretrained("espnet/fastspeech2_conformer")
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan", torch_dtype=torch.float16, device_map="auto")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt").to("cuda")
input_ids = inputs["input_ids"]
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"]
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)Co-authored-by: Steven Liu <[email protected]>
Co-authored-by: Steven Liu <[email protected]>
Co-authored-by: Steven Liu <[email protected]>
Co-authored-by: Steven Liu <[email protected]>
Co-authored-by: Steven Liu <[email protected]>
Co-authored-by: Steven Liu <[email protected]>
#36979
Before submitting
Pull Request section?
to it if that's the case.
documentation guidelines, and
here are tips on formatting docstrings.