Current cortex_compactor_blocks_marked_for_no_compaction_total value is lost upon redeployment #4727
Comments
This is not a brand new metric introduced on 4d751f2? |
That's correct. I'm running compactor version that incorporates this commit. |
|
So there is no current behaviour that was changed on that commit, right? This metric is a counter and.. starting again in 0 is expected i guess. You may wanna do something like |
The way I think of it - the metric was added, but there is a chance an edge case of "what happens when we gotta create a new set of pods with an already existing storage that had some blocks marked as no deletion" was not thought of. But I might be looking at the design from the wrong perspective?
As I said, I might be in the wrong here, but the way I see it is the metric should show the total count of all blocks that are in the storage and were marked as no deletion. Instead it seems (either purposely or by design) to show the current count of no compaction blocks for the current set of pods. Considering it's in the nature of K8s to replace pods I think that the latter is not very useful? Similarly, upon redeployment Cortex properly shows the current block count (instead of counting only newly created blocks).
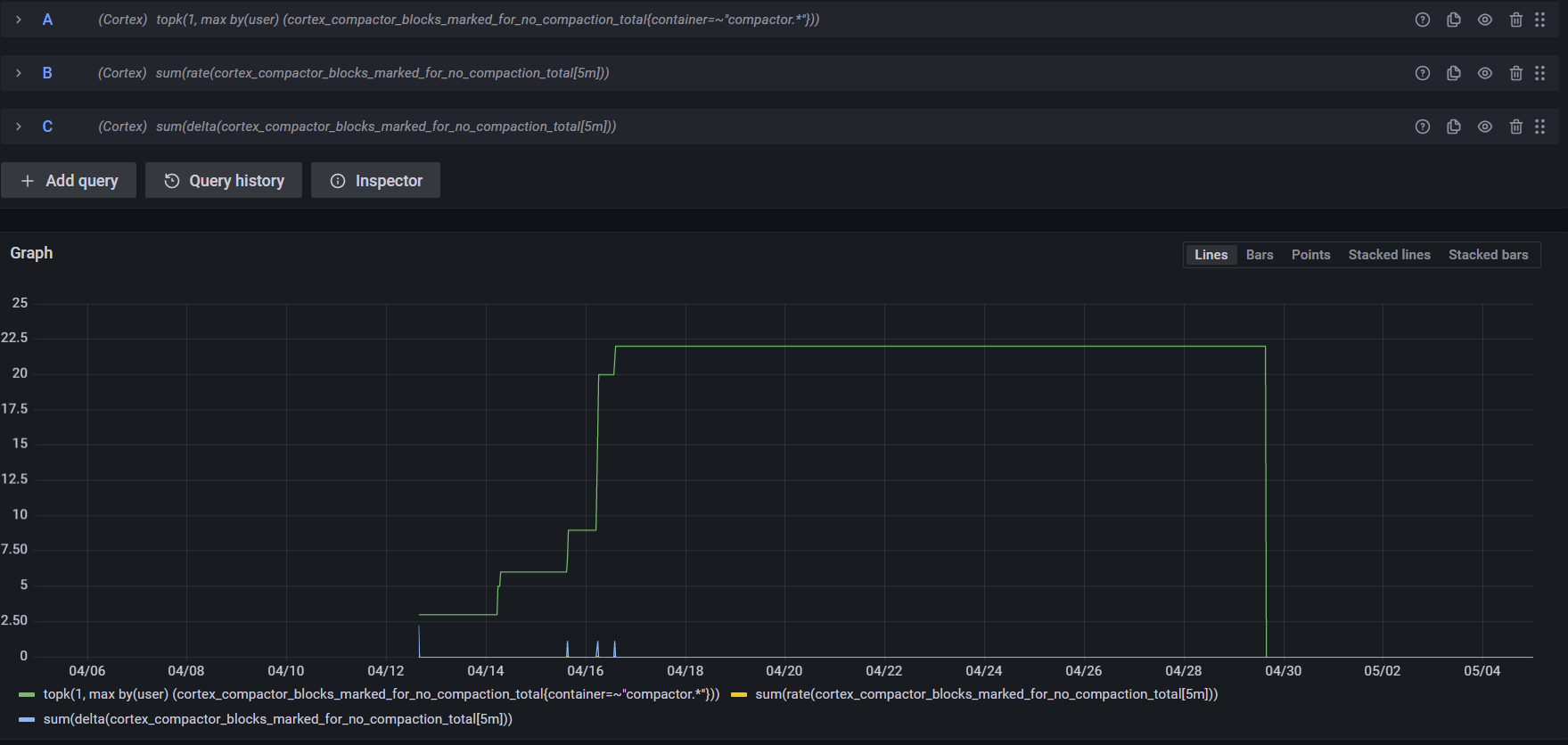
Well, that doesn't work. Sharing a screenshot below, the first query is the one I use in my dashboards:
|
|
I could run something like |
|
Hi @shybbko I can't really see the graph for But would you mind trying changing Also set the |
|
Seems we want a gauge not a counter here if i'm understanding this correctly, right? A metric that shows the state of my storage RIGHT NOW (In other words, how many blocks are marked to skip on my entire storage). The problem is that this metric is created by Thanos. What is the goal of that metric? Are you able to recover those blocks and so you can have the metric always 0? |
|
Hi @alvinlin123 !
With the range of 30 days and max Y axis value being 25 it's almost invisible with the top value of around 0.008, but it's there. It's just a matter of screenshot resolution, apologies.
There you go (the range was cut to the relevant period, so it's different from the previous screenshot):
Quite honestly I don't know which flag in Cortex configures self-scrape interval? |

I can work with the current design and something like What I personally need is the latter, as I am interested in knowing how many blocks I have are (because of various reasons) imperfect and marked as no compaction. Based on that I can later investigate them. So far the no compaction blocks I've got I am unable to make compaction-ready, as they contain out of order samples. But that's a different story. |
|
Alright I think I misunderstood the issue since the beginning.
So, I think we will need to create a new metric to keep track of how many blocks are currently marked for no compact. |
What does it take to test it? The bare minimum? Compactor only, judging by the code? What I mean is that I could prepare a simple test env and then build an image based on this branch in order to test a single pod. However I am afraid whether it would take more resources? |
|
This should not take any more resource … it is just counting how many no compaction markers is found on the same loop that already exists to build the bucket index. |
|
So deploying compactor pod only is fine here, correct? |
|
Yeah.. it should work.. |
|
Seems to work fine. One remark though: with |
|
Nice.. we only need that on first time to migrate the marks to the global folder |
|
It would be nice to have the reason as well I guess … |
Not sure if I get you...? |
|
The reason label ..
for that we would need to read the markers.. we can do after if needed I guess |
|
Oh, that. For my needs that's not that relevant, but I do agree it would be a fine addition. |
|
I think now the question is .. should we keep both metrics? If so what’s should be the name of this new metric ? @alvinlin123 thoughts ? Ps: this new metric is only available if bucket index is enabled .. I think is fine |
|
Ok.. I open the PR.. I changed the metric name to be aligned with the other one we have for the deletion marks: |
|
Great! I appreciate the effort! |
Describe the bug
Cortex Compactor, upon pod redeployment, loses the current value of
cortex_compactor_blocks_marked_for_no_compaction_totalmetric.This might or might not be affected by the fact, that currently I'm running Cortex 1.11.0 deployed via Cortex Helm Chart 1.4.0 with all bells and whistles (caches, key stores etc) but without Cortex Compactor pod. It's deployed separately and with minimum configuration possible. It's running cortex:master-bb6b026 version in order to incorporate 4d751f2 which introduced fix to compaction process which was blocking compaction in my env.
To Reproduce
Steps to reproduce the behavior:
cortex_compactor_blocks_marked_for_no_compaction_totalstarts showing value >0Expected behavior
Current
cortex_compactor_blocks_marked_for_no_compaction_totalvalue is not lost upon Cortex redeploymentEnvironment:
GKE 1.21
Cortex 1.11.0 deployed via Cortex Helm Chart 1.4.0 (without compactor pod)
Cortex Compactor cortex:master-bb6b026 deployed separately
Storage Engine
Blocks
Additional Context
n/a
The text was updated successfully, but these errors were encountered: