dft street manager doc 0002 solution architecture
- Introduction
- Functional view
- Information view
- Deployment view
- Operations view
- Development principles
- Security overview
- Testing strategy
- Technical overview of Alpha
Street Manager is a centralised system for collecting and processing street work information, used by Promoters (utility companies) and Local Authorities.
The vision of the project is:
To transform the planning, management and communication of street works through open data and intelligent services to minimise disruption and improve journeys for the public.
This document is aimed at Product Delivery, Software Architects, Delivery and Operations teams.
In this document, we will describe the system from different viewpoints so that each member of the delivery/operations team have a shared understanding of the system.
We are using a cross functional agile approach to delivery, so all functions of the team are represented (dev/test/operations).
We are taking a DevOps approach to implementation, including fully automated testing, deployment and security testing. Teams are responsible for pushing their code from development to live, taking all non-functional requirements into consideration when starting and completing a story.
We use the C4 approach to illustrating the overall system architecture. See draw.io for the source of diagrams below.

NOTES:
- Assuming GOV.UK Notify for email/sms/post notifications.
- NSG data will be loaded from regular data dumps from GeoPlace which will be imported into the application database. The data will be used in mapping and business logic, initially directly as data but may be separated into another service later if necessary.
- See draw.io diagram bottom tabs for how the systems will be created/updated between phases

Undertaker web
Separate front end for serving undertaker HTML requests so that it can handle load and scale independently.
Requires common elements: GDS styles, mapping Javascript, security filters.
Local Highways Authority web
Separate front end for serving undertaker HTML requests so that it can handle load and scale independently.
Requires common elements: GDS styles, mapping Javascript, security filters.
Work API
API for handling works interactions.
External Work API Gateway
Exposes specific work API functions to external users, such as GeoJSON mapping requests for client browser mapping and external API integration for works events.
Scenarios show how the components of the solution collaborate on key behaviours of the solution.
See service design board for details on user scenarios and journeys.

Task API
API for adding/checking tasks. Tasks are regularly scheduled, fragile external calls to integration points or long running jobs required by the system. They should record their status (created, in progress, completed, failed) and capable of re-running in case of failure. Only internal components should call the Task API.
Requires common elements: database change management, API documentation.

Registration and admin web
Separate front end for registration and user administration. Allows invited users from Undertakers and LHAs to register themselves and their organisation, with admin functions for managing their users and organisation details.
Requires common elements: GDS styles, mapping Javascript, security filters.
Party API
API for handling all updates to Person and Organisation data, persisting into database. Data will be modelled based on the Universal Person and Organization Data Model approach. Separate to scale and manage independently as other systems may require party details, such as authentication and registration.
Requires common elements: database change management, security filters, API documentation.
Authentication web
Common web component used by users to authenticate with the service. Other web components will call or redirect via OAuth2 Grant Authorisation Token flow (see here) to this component to force authentication. It will also supply users group membership details for authorisation checks (RBAC).
NOTE: This may be an external managed service such as AWS Cognito.
Street Manager provides two ways of accessing mapping data. Users may use either of the Street Manager websites. Or users may use their local mapping tools, accessing Street Manager via the standard WFS and WMS protocols. Street Manager uses separate resources to address these needs.

The left hand side of the figure shows the stack for users' own mapping tools. Note that the mapping tool's WFS and WMS requests include a valid basic authorisation header. TBD: management of basic auth credentials.
- The Mapping Gateway intercepts WFS / WMS calls from the user mapping tool. It provides TLS termination and simple IP load balancing. TBD: it may also check authorisation headers. TBD: the gateway will either be implemented by nginx deployed as part of the application, or by a cloud service.
- GeoServer is a standard component that is configured for particular data sources. It is a Java application. It will be containerised. TBD: GeoServer may additionally check for a valid basic auth header. TBD: monitoring; at very least, we have JMX support.
- We use a read only replica to keep the GeoServer workload away from our master DB. For the same reason, replication will be asynchronous.
The right hand side of the figure shows the stack for the SM web interface. Note that the browser already has a valid login session and has already loaded a Street Manager mapping page.
- The browser triggers JavaScript according to user actions, such as panning the map and selecting / deselecting layers. The bespoke JavaScript makes calls to the RESTful Works API, including the session token in the header.
- These calls are intercepted by the Gateway, which terminates TLS, validates the session token (redirecting if invalid) and passes the call through to Works API
- Works API returns resources that include GeoJSON to represent works geometry.

Reporting DB
Read replica database of works data. Will allow limited access to specific users who require direct access to all works data (e.g. DfT Staticians). Other users may be allowed restricted access via SQL to custom views with limited work details.
NOTE: Initially we will use a single read replica for both reporting and subscriptions but this may change if load is too heavy from either.
External Works Data API
Exposes works data to interested parties, such as Undertakers and app developers. This will be the main way for authenticated users to access works data, authorisation will restrict which records they can access (e.g. no commercially sensitive data).
Requires common elements: security filters, API documentation.
Subscription API
Exposes feeds of activity related to works. Will use a subscription based approach (atom feed) so interested parties can see what has changed on their works.
Full details on the Data model and standards approach are documented here.
- SM will enforce organisation-level access policies on a single DB instance.
- SM will support messages (e.g. permit requests) in draft state and potentially not passing all validation rules, for UI access, only. The API made available to promoters will support only messages in their final state, fully valid.
- SM will preserve all successfully created messages between promoters and authorities immutably: requests, refusals, variations, and so on. Shared entities with mutable state will be summaries of these primitive messages. To that extent, the SM information model will be event-orientated.
- SM will support occurence times that precede insertion (capture) times, allowing SM to "catch up" during DR without losing time information.
Street Manager will take data from a number of external sources, using it for business logic and to present to users. This is documented here.
See the Reporting and archive system containers diagram for details and here for implementation details.
In Street Works industry parlance, reporting includes any operational queries where the user needs to export results for wider distribution.
Analysis includes aggregate queries, whether for wider distribution.
Intially, SM will provide a SQL endpoint to a read replica for DfT analytical use. DfT statisticians will access this via VPN from their office network.
Overview of build pipeline, quality gates etc. will be outlined here, these will be standard across the project.
- Maintain a code repository
- Ensure each microservice app to stored in its own dedicated repository
- Treat config, and data, separately from the app code. But all must be version controlled.
- Automate the app build, from code into a self-contained, stateless container
- Make the build self-testing
- Every commit (to master) should be built and deployed
- Build one container artefact per service, promote that identical artefact many times through all environments
- Everyone in team should be encouraged to view build status, and troubleshoot issues
- Ensure the build completes quickly
- Fully automate the deployment of apps, config and data across all environments
- Test artefacts in production-identical environments
- Each microservice should form the unit of deployment. ie, release built microservice containers (and their related config+data) independently from one another
- Make it easy to access the latest builds
The project will use a feature branch workflow:
- Developers work on feature branches until their work is thoroughly tested and is signed off by the product owner.
- They produce a squashed commit that combines all the changes on that branch
- Merging to master entails commitment to release order. The team tests merge commits and tags them as release candidates
- Merging a feature to master means that other features that are in-flight will have to rebase their code
- Fixes are treated as urgent features. That is, other in-flight features should wait on branch for the fix to be merged to master so that the rebasing overhead falls on them rather than on the urgent fix
See here for a tutorial.
This model is based of the "DVSA MOT Code Workflow - 27/02/2017" whitepaper.
High level overview of how we will work.

To maintain separation of concerns and make our deployment/release process flexible, we will have a container per component/service in the solution. Source code, configuration templates and charts will be stored in separate repositories.
Separate repositry will be used to control the configuration, state and secrets for the infrastrucute solution.
Githooks and webhooks against these repositories are used to trigger builds on CI.
Images should be built consistently, so dependencies should be resolved and fixed at point of build. This is done for node with npm shrinkwrap which generates a file fixing the npm install to specific dependency versions. This should be done as part of development each time package.json is updated, to ensure all developers as well as images use the exact same versions of packages.
On each commit to ANY branch the image is build and tested.
On pull request, test merge is being performend before building and testing the image.
On each commit to develop branch the image is build and tagged twice:
- develop version tag is calculated using
git rev-parse HEAD- this will use actuall commit SHA - latest
Once we're ready to release, a proper version git tag will be created ("v1.0.1"), added to already build image and promoted across environments.
The "develop" tagged image is used as the latest current version of the image to be deployed as part of automated builds to the Development environment, in the develop branch docker-compose.yml all referenced images will use that tag.
The version number tagged image, "v1.0.1", is used as a historic fixed version for traceability, so for specific releases the tagged master docker-compose.yml will reference specific versioned images. This means we have a store of built versioned images which can be deployed on demand to re-create and trace issues.
All containers for microservices will be versioned independently using SEM approach.
All containers will be build with Twelve-Factor App methodology approach. Because of this, we can use the public Docker Hub repository (secrets content will be passed as environmental variables). Docker Hub supports hosting and building images from public repositories, with builds triggered either manually by API (preferred, to keep in control by our CI) or GitHub service.
If we need to have a private image repository, this is possible by using Cloud Platform specific services (AWS Elastic Container Repositor).
Gate 1 - Developer merge requests
- Code review by developer/Tech Lead not involved in changes
- Code quality/Build/Unit tests must pass against feature branch
- additional tests, such as UI/Performance tests must pass locally on reviewers machine
Gate 2 - CI
- Builds and tests the Code
- Tags build artifacts to allow tracing back to commit/build
- Deploys build artifacts to appropiate environment
- Triggers appropiate test runs, such as UI cross browser/Performance/Security/Accessibility
Gate 3 - Deployment to staging
- Promotes release to separated staging/production environment
- Manual operation, requires approval
- Triggers appropiate test runs, such as smoke tests
Gate 4 - Deployment to production
- Manual operation to promote staging release to production for live use, requires approval
TBC after CI spike.
SM will integrate with a web analytics service, and will not deploy a self-hosted solution. On grounds of cost-effectiveness, the most likely candidate is Google Analytics Pro. In that case, SM would be what is termed a property. It may sit within a DfT account, or another government account.
The selected tool will conform to the W3C CEDDL standard and we will integrate with our web tier on that basis. This will mitigate lock-in and will keep open options for future tag management by DfT staff who do not have development skills.
As part of the service standard we must integrate with the GOV.UK performance platform.
This will involve engaging with the performance platform team, agreeing what metrics will be supplied and the technical effort in sending these metrics.
Technically the metrics will be sent as a regular task (daily or monthly) via an API call.
Real time monitoring solution will be build around Prometheus (metric collecting) and Grafana (visualization) stack. Both tools are well proven by Open Source community, but also used across other projects (SMART and DVSA MOT2 as an examples). These applications will be hosted inside Kubernetes cluster on dedicated workers to not interrupt any other environments. Kubernetes also comes with Heapster and cAdvisor enabled, which will allow us to get as deep as pod/container cpu/memory usage.
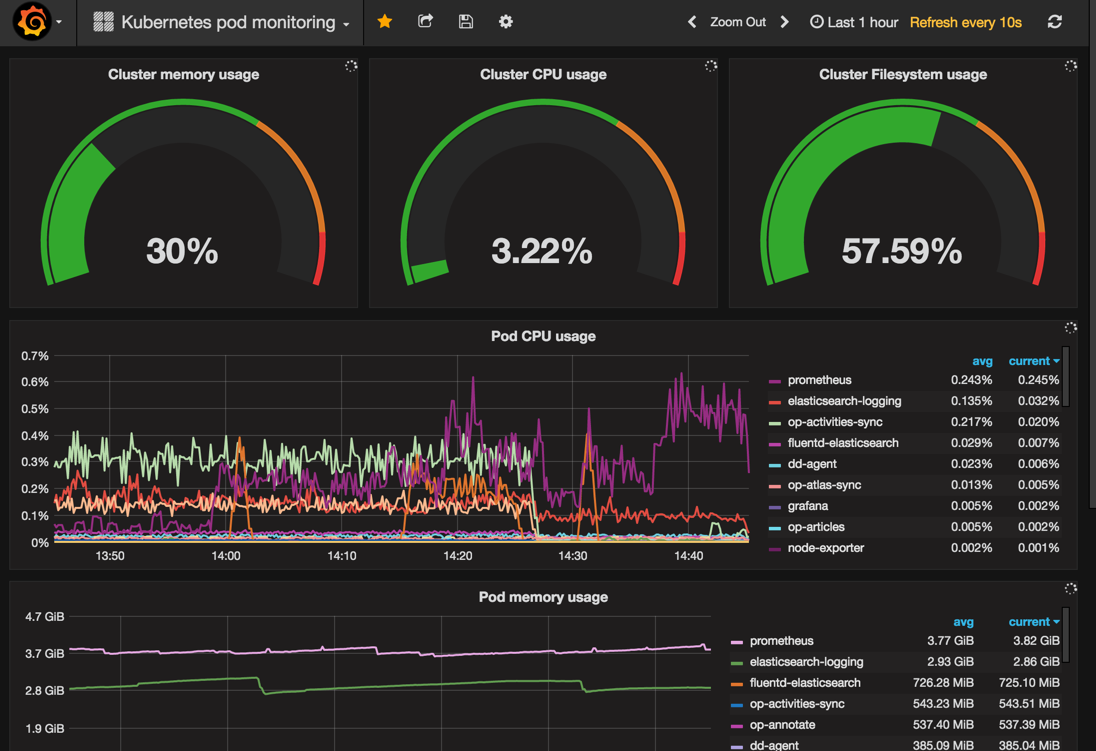
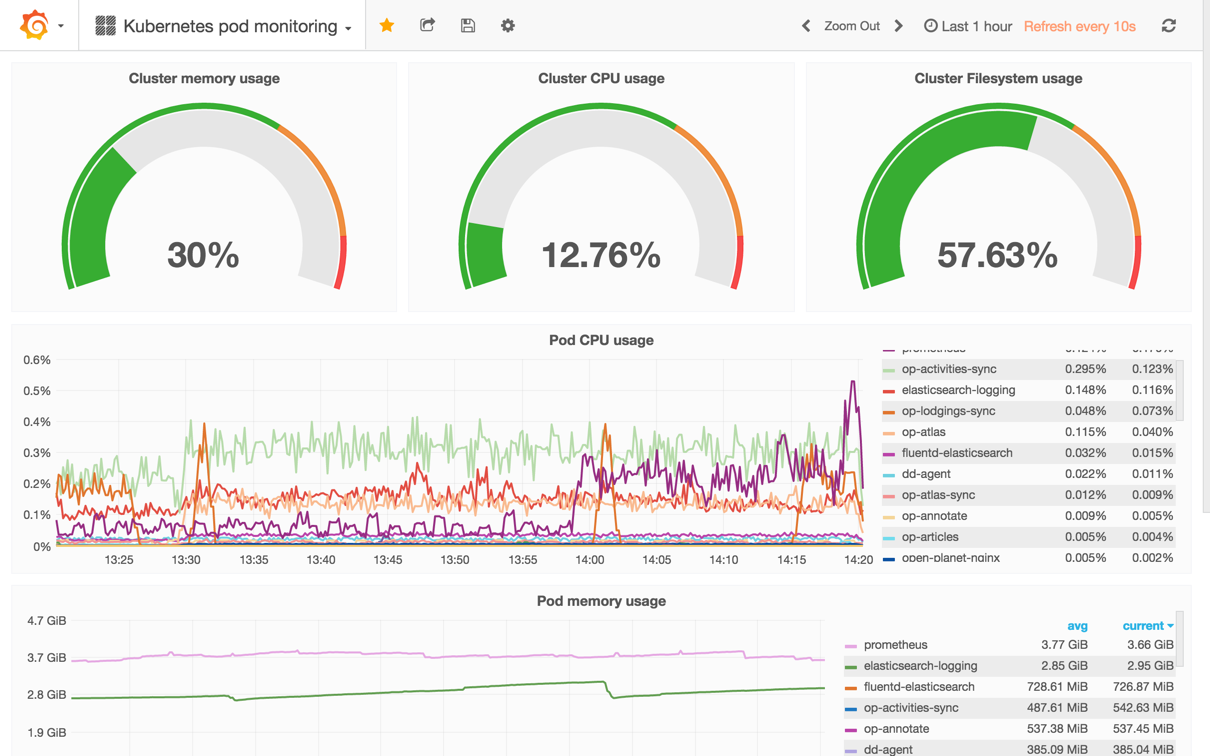
All components will log important events, such as requests and integration/task events. Logs will use JSON emitters (bunyan) and use common names for data items ("username", "Interaction identifier"). See here for recommendations on data to include and exclude (for security).
As a minimum, components should be logging:
- Severity
- HTTP method
- URL
- User identifier
- Timing info (timestamp, start/stop duration)
- Interaction identifier (session id maintained across common interaction requests)
- Source name (component)
- Source address
- Event type
Error logging should also use a consistent form and allow tracing of errors to code location.
The application will be storing important event data in the database, so logging will not be used for auditing, see data model for more details.
As for log aggregation we will use third party provider (due to the cost and complexity involved with building self hosted solution on our own). Kubernetes usually came with fluend, which essentially is a data collector for unified logging layer. It supports many plugins for datasources and outputs.
Options we're looking at:
- AWS hosted Elasticsearch Service (AES) + Kubernetes hosted Kibana - this stack is very well proven to work
- Sumologic
- Datadog
All components should expose:
-
/healthcheckendpoint which returns 200 if healthy based on dependency checks (database/API etc.) -
/statusendpoint which returns 200 if application is alive (used to ping service availability) -
/metricsendpoint which returns Node application metrics such as CPU/memory usage and (using appmetrics)
Each component should implement these consistently, so they can be used in monitoring the same for all existing and new components.

- Node (v8.x.x, latest LTS) - JavaScript language for server side web and api logic
- Express - Node web framework
- OpenLayers - JavaScript mapping framework
- PostGres with PostGIS extensions - Relational database with GIS functions
Rationale:
- The application will require significant client side JavaScript so using NodeJS for web/api logic means a single consistent language for the application with good support for including GDS styles in the application
- Express is the most common and flexible web framework for Node
- OpenLayers is a mature JavaScript mapping library and existing GOV.UK solutions have passed Alpha assessment using it (Land Registry LLC)
- PostGres scales extremely well, has good managed RDB support in hosting providers and mature GIS extensions
Useful links:
- Node with TypeScript
- APVS ODP - GOV.UK node project and source
- Node API generation with Typescript and Swagger
- turbolinks - preserve map state in browser with back/forward navigation
- TypeScript/es6/es2015 blog
The solution should be split into small separate components which can be released independently. This aids rapid development, allows independent scaling and Node applications are more manageable when kept simple.
Useful links:
See API design principles are documented here.
The definition of done is defined here.
The security overview is defined here.
The test strategy is documented here.
The technical overview of Alpha is documented here.