Czkawka for now contains three independent frontends - the terminal app and two graphical apps which share the core module.
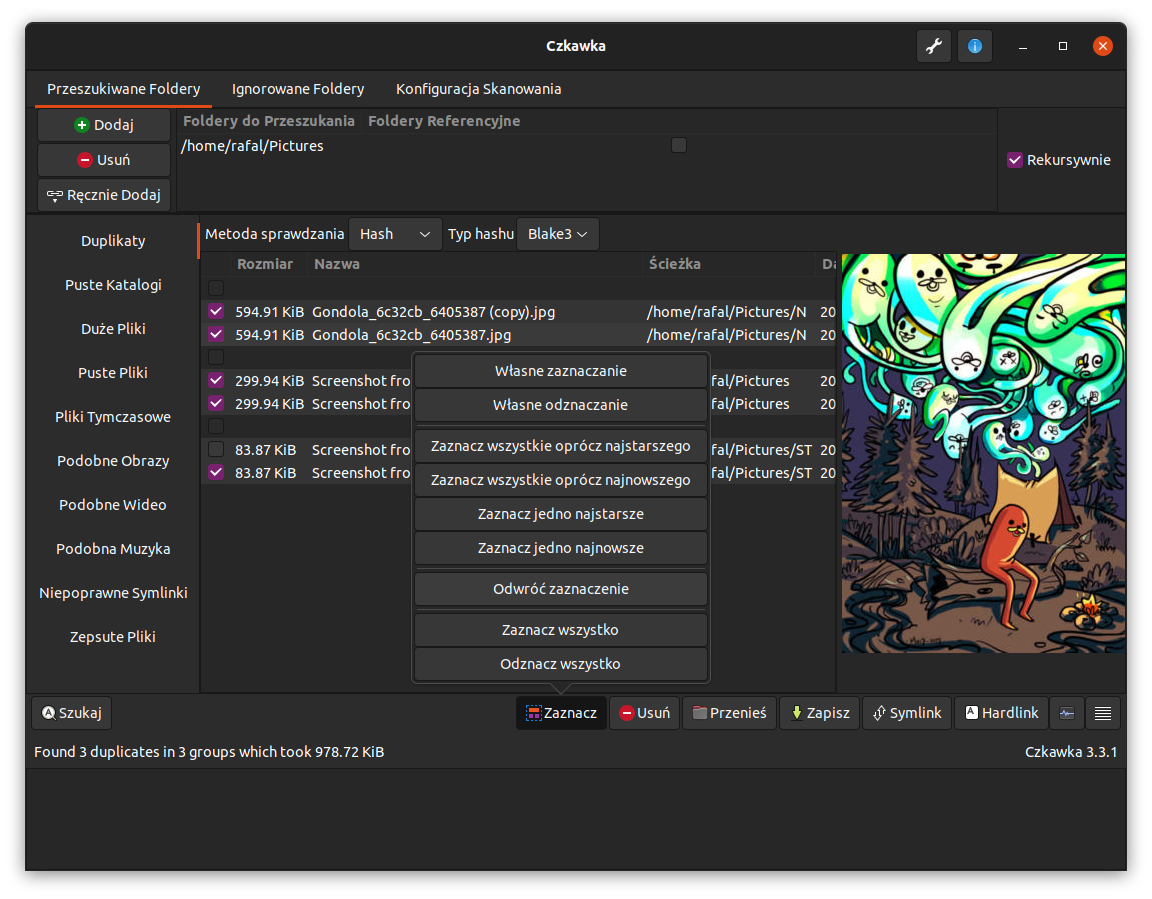
The GUI is built from different pieces:
- 1 - Image preview - it is used in duplicate files and similar images finder. Cannot be resized, but can be disabled.
- 2 - Main Notebook to change used tool.
- 3 - Main results window - allows to choose, delete, configure results.
- 4 - Bottom image panels - contains buttons which do specific actions on data(like selecting them) or e.g. hide/show parts of GUI
- 5 - Text panel - prints messages/warnings/errors about executed actions. User can hide it.
- 6 - Panel with selecting specific directories to use or exclude. Also, here are specified allowed extensions and file sizes.
- 7 - Buttons which opens About Window(shows info about app) and Settings in which scan can be customized
GTK GUI is fully translatable.
For now at least 10 languages are supported(some was translated by automatic translation, so may not be perfect).
It is possible to open selected files by double-clicking on them.
To open multiple file just select desired files with CTRL key pressed and still when clicking this key, double-click at selected items with left mouse button.
To open folder containing selected file, just click twice on it with right mouse button.
To invert a selection of files, click on a file with the middle mouse button, and it will invert the selection of the other files in the same group.
By default, current path is loaded to included directory and excluded directories are filled with default paths.
It is possible to override this, by adding arguments when opening app e.g. czkawka_gui /home /usr --/home/rafal --/home/zaba which means that /home and /usr directories will be checked and /home/rafal and /home/zaba will be excluded.
When using additional command line arguments, saving at exit option become disabled, so this current info about directories will not be saved until user save it manually.
Both relative and absolute path are supported, so user can use both ../home and /home.
After adding a path it is possible to mark one or more paths as a Reference folder. Files in the Reference folder cannot be acted upon, e.g. selected, moved or removed. This behaviour can be useful if you want to leave a folder untouched, but still use it for comparison against others.
Czkawka CLI frontend is great to automate some tasks like removing empty directories.
To get general info how to use it just try to open czkawka_cli in console czkawka_cli
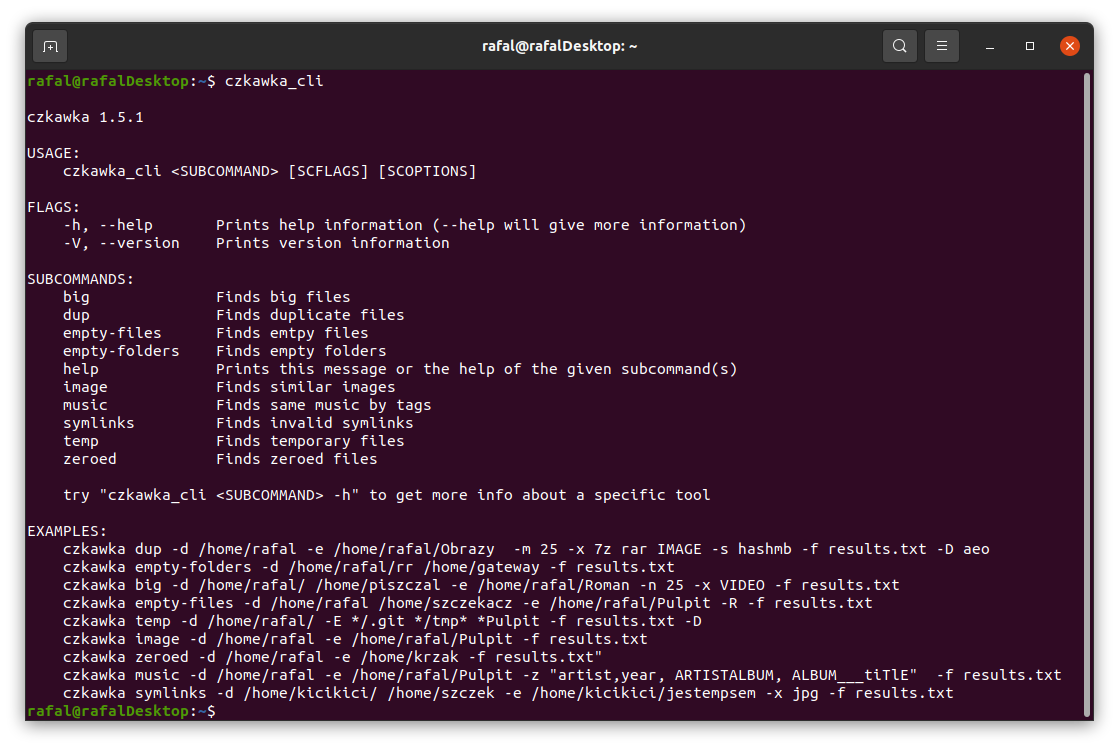
You should see a lot of examples how to use this app.
If you want to get more detailed info about certain tool, just add after its name -h or --help to get more details.
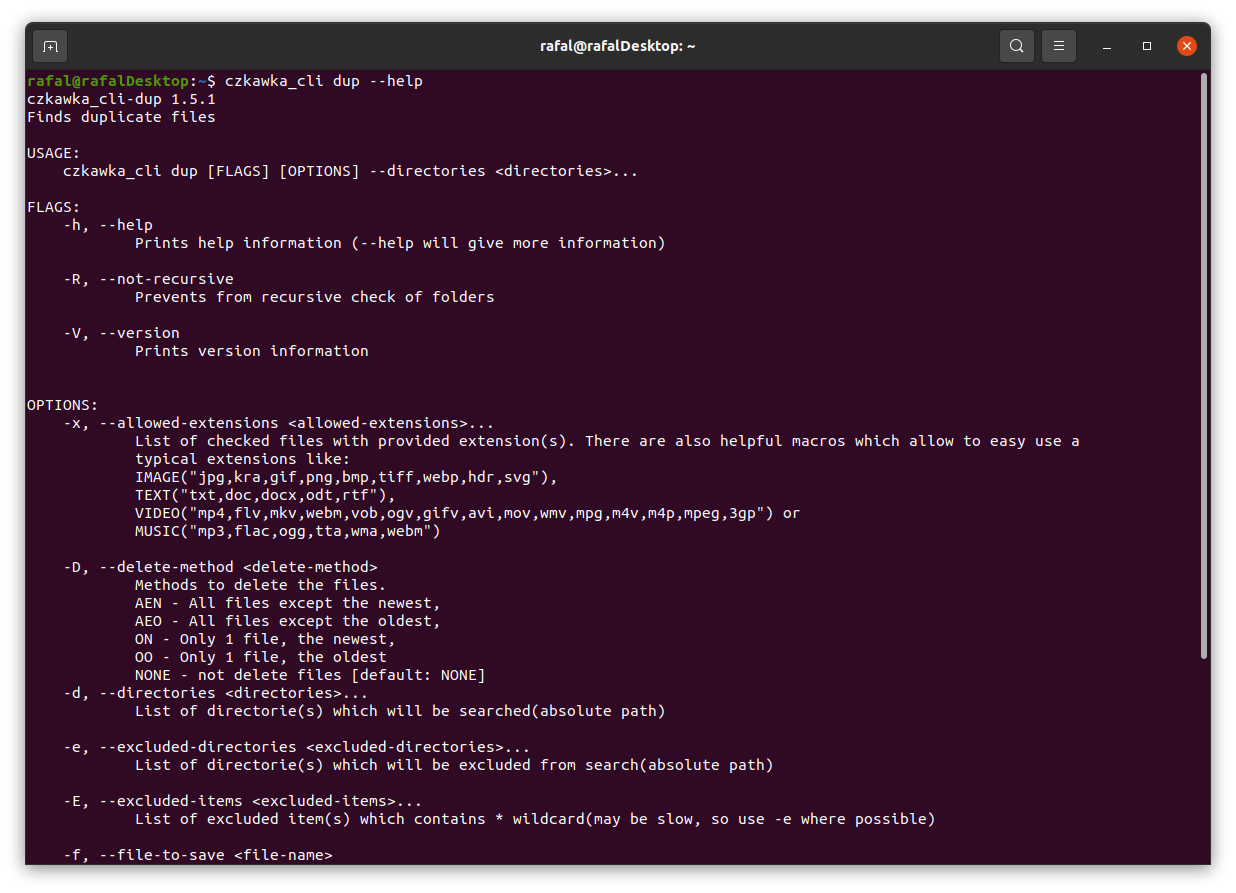
By default, all tools only write about results to console, but it is possible with specific arguments to delete some files/arguments or save it to file.
App returns exit code 0 when everything is ok, 1 when some error occurred and 11 when some files were found.
Currently, Czkawka stores few config and cache files on disk:
czkawka_gui_config.txt- stores configuration of GUI which may be loaded at startupcache_similar_image_SIZE_HASH_FILTER.bin/json- stores cache data and hashes which may be used later without needing to compute image hash again. Each algorithms use its own file, because hashes are completely different in each.cache_broken_files.txt- stores cache data of broken filescache_duplicates_HASH.txt- stores cache data of duplicated files, to not suffer too big of a performance hit when saving/loading file, only already fully hashed files bigger than 5MB are stored. Similar files with replacedBlake3to e.g.SHA256may be shown, when support for new hashes will be introduced in Czkawka.cache_similar_videos.bin/json- stores cache data of video files.
It is possible to modify files with JSON extension(may be helpful when moving files to different disk or trying to use cache file on different computer). To do this, it is required to enable in settings option to generate also cache json file. Next file can be changed/modified. By default, cache files with bin extension are loaded, but if it is missing(can be renamed or removed), then data from json file is loaded if exists.
Config files are located in this path:
Linux - /home/username/.config/czkawka
Mac - /Users/username/Library/Application Support/pl.Qarmin.Czkawka
Windows - C:\Users\Username\AppData\Roaming\Qarmin\Czkawka\config
Cache should be here:
Linux - /home/username/.cache/czkawka
Mac - /Users/Username/Library/Caches/pl.Qarmin.Czkawka
Windows - C:\Users\Username\AppData\Local\Qarmin\Czkawka\cache
it is possible to change cache/config location by using CZKAWKA_CONFIG_PATH and CZKAWKA_CACHE_PATH env
e.g.
CZKAWKA_CONFIG_PATH="/media/rafal/Ventoy/config" CZKAWKA_CACHE_PATH="/media/rafal/Ventoy/cache" krokiet
It is possible to create portable version of app, by using running czkawka/krokiet with such script from pendrive:
open_czkawka.sh - on pendrive(along with czkawka/krokiet binary)
#!/bin/bash
CZKAWKA_CONFIG_PATH="$(dirname "$(realpath "$0")")/config"
CZKAWKA_CACHE_PATH="$(dirname "$(realpath "$0")")/cache"
./czkawka_gui- Speedup of CPU bounds tasks with LTO
You can easily compile app with lto, by adding/modyfing in
Cargo.tomlfile, this lines(small performance boost, big decrease in binary size):
[profile.release]
lto = "thin" # or "fat"
- Speedup of CPU-bound tasks using native CPU optimizations When doing CPU bound tasks, compiling with native CPU optimizations can give a significant speedup(speedup on x86_64_v4, when hashing images is usually 10-20%):
RUSTFLAGS="-C target-cpu=native" cargo build --release
or adding it globally to ~/.cargo/config.toml
[target.x86_64-unknown-linux-gnu]
linker = "clang"
rustflags = [
"-C", "target-cpu=native",
]
- Faster checking for similar images
The new
fast_image_resizefeature enables faster image resizing using a specialized crate. The speedup varies depending on image size: from no noticeable improvement for very small images to a 30–200% increase for larger ones. This feature is enabled by default starting from version 9.0 but can be disabled if needed. - Manually adding multiple directories
You can manually edit config fileczkawka_gui_config.txtand add/remove/change directories as you want.
After set required values, configuration must be loaded to Czkawka. - Slow checking due long loading/saving to cache step
If you checked before a large number of files (several tens of thousands), then the required information about all of them are loaded and saved to the cache, even if you are working with only few files.
You can rename one of cache file which starts fromcache_similar_image(to be able to use it again) or delete it - cache will then regenerate but with smaller number of entries and this way it should load and save cache faster. - Not all columns with data(modification date, file size) are always visible in gui
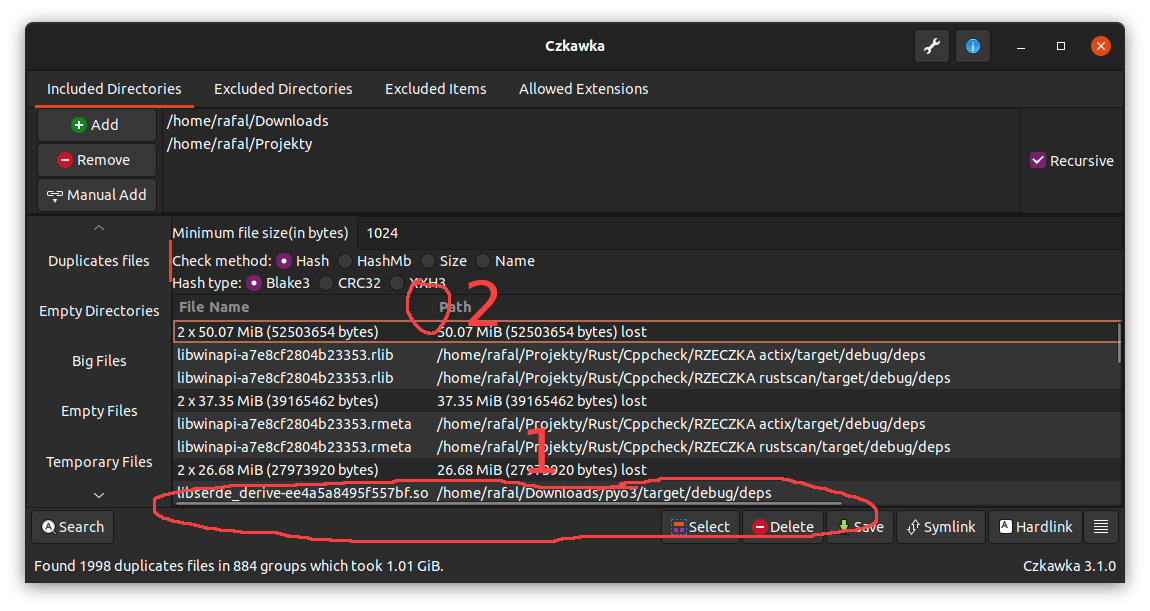
For now it is possible that some columns will not be visible when some are too wide.
There are 2 workarounds for now- View can be scrolled via horizontal scroll bar (1 on image)
- Size of other columns can be slimmed (2)
This is checked if is possible to do in #169
- Opening parent folders
- It is possible to open parent folder of selected items with double click with right mouse button(RMB) it is also possible to open such item with double click with left mouse button(LMB).
- Faster scanning for big number of duplicates
By default for all files grouped by same size are computed partial hash(hash from only of start 4KB each file). - Such hash is computed usually very fast, especially on SSD and fast multicore processors.
But when scanning a hundred of thousands or millions of files with HDD or slow processor, typically this step can take much time.
In settings exists optionUse prehash cachewhich enables caching such things.
It is disabled by default because can increase time of loading/saving cache, with big number of entries. - Permanent store of cache entries
After each scan, entries in cache are validated and outdated ones(which points at non-existent files) are removed.
This may be problematic when scanning external drivers(like pendrives, disks etc.) and later unplugging and plugging them again.
In settings exists optionDelete outdated cache entries automaticallywhich automatically clear this, but this can be disabled.
Disabling such option may create big cache files, so buttonRemove outdated resultswill do it manually. - Partial scanning If you know that you can't scan all files at once, you can still try to scan all files and during scan just stop it, so already calculated hashes/data will be saved to cache and will speedup later scans.
Duplicate Finder allows you to search for files and group them according to a predefined criterion:
-
By name - Compares and groups files by name e.g.
/home/john/cats.txtwill be treated like a duplicate of a file named/home/lucy/cats.txt. This is the fastest method, but it is very unreliable and should not be used unless you know what you are doing. -
By size - Compares and groups files by their size (in bytes and perfect matches only). It is as fast as the previous mode and usually gives better results with duplicates, but I also do not recommend using it if you do not know what you are doing.
-
By size and name - A mode that first compares files by size and then by name. Just like checking by size and name, this mode is not reliable.
-
By hash - A mode containing a check of the hash (cryptographic hash) of a given file which determines with great probability whether the files are identical.
This is the slowest, but almost 100% sure way to compare the files for being the same.
Because the hash is only checked inside groups of files of the same size, it is practically impossible for two different files to be considered identical.
It consists of 3 steps:
-
Grouping files of identical size - allows you to throw away files of unique size, which are already known to have no duplicates at this stage.
-
PreHash check - Each group of files of identical size is placed in a queue using all processor threads (each action in the group is independent of the others). In each such group a small fragment of each file (2KB) is loaded in turn and then hashed. All files whose partial hashes are unique within the group are removed from it. Using this step usually allows me to reduce the time of searching for duplicates almost by half.
-
Checking the hash - After leaving files that have the same beginning in groups, you should now check the whole contents of the file to make sure they are identical.
-
Searching for empty files is easy and fast, because we only need to check the file metadata and its length.
At the start, a special entry is created for each directory, including its parent path (unless it is a folder directly selected by the user) and a flag indicating whether the directory is empty. Initially, all directories are assumed to be potentially empty.
First, user-defined folders are added to the pool of directories to be checked.
Each folder is then examined to determine its status:
- If it is a folder – it is added to the check queue as potentially empty (FolderEmptiness::Maybe).
- If it contains any files or subdirectories – it is marked as not empty (FolderEmptiness::No). In this case, all parent directories, both direct and indirect, are also marked as not empty.
Example
Consider four folders that may be empty: /cow/, /cow/ear/, /cow/ear/stack/, /cow/ear/flag/.
If /cow/ear/flag/ contains a file, then:
- /cow/ear/flag/ is marked as not empty.
- Its parent folders /cow/ear/ and /cow/ are also marked as not empty.
- However, /cow/ear/stack/ may still be empty.
Finally, all folders still marked as FolderEmptiness::Maybe are considered empty by default.
For each file within the given path, its size is read. Then, depending on the mode, a specified number of either the smallest or largest files are displayed.
Searching for temporary files is done by comparing their extensions against a predefined list.
Currently, the following names and extensions are considered temporary:
["#", "thumbs.db", ".bak", "~", ".tmp", ".temp", ".ds_store", ".crdownload", ".part", ".cache", ".dmp", ".download", ".partial"]
This method removes only the most common temporary files. For more thorough cleanup, I recommend using BleachBit.
To find invalid symlinks, we first need to identify all symlinks in the given path.
Once symlinks are located, each one is checked to determine its target. If the target does not exist, the symlink is added to the list of invalid symlinks, as it points to a non-existent path.
The second mode attempts to detect recursive symlinks. However, this feature is currently non-functional and incorrectly reports an error related to a non-existent target. The intended implementation works by counting the number of symlink jumps, and if a certain threshold (e.g., 20) is exceeded, the symlink is considered recursive.
Tags are limited to artist, title, year, bitrate, genre, and length.
Process
- Collect all music files with one of the following extensions:
[".mp3", ".flac", ".m4a"] - Read the tags for each file
Additionally in duplicate tags mode
- User selects tag groups that will be used to compare files
- Tags like
artistare simplified by:- Removing all non-alphanumeric characters
- Converting text to lowercase
- Removing everything inside parentheses, but only if approximate comparison is selected (e.g.,
bataty (feat. romba)is treated asbataty)
- Only non-empty tags are collected
Additionally in similar content mode
- If title-based comparison is selected, files are first grouped by simplified title to reduce the number of hashes that need to be calculated
- A hash is generated for each file
- Hashes are compared, respecting the user-defined similarity threshold and the minimum required length of matching fragments
After checking all tags, results are shown in a table.
A tool for detecting similar images that may differ in aspects such as watermarks, size, or compression artifacts.
Currently, it works well for images that have not been rotated.
- Collecting Images
- The tool gathers images with specific extensions, including RAWs, JPEGs, and many others.
- Loading Cached Data
- Previously computed hashes are loaded from a cache file to avoid re-hashing the same files
- Cache entries pointing to non-existent files are automatically removed by default(this can be disabled in settings)
- Generating Perceptual Hashes
-
Image is resized to 8x8, 16x16, 32x32, or 64x64 pixels (inside
image_hashercrate) -
A perceptual hash is computed for each image that is not already present in the cache
-
Unlike cryptographic hashes, which produce completely different outputs for slight variations:
11110 ==> AAAAAB 11111 ==> FWNTLW 01110 ==> TWMQLAPerceptual hashes generate similar outputs for similar images:
11110 ==> AAAAAB 11111 ==> AABABB 01110 ==> AAAACB
- Storing and Comparing Hashes
- Computed hash data is stored in a specialized tree structure, allowing efficient comparison using Hamming distance.
- The hashes are then saved to a file, ensuring images don’t need to be rehashed in future runs.
- Each hash is compared with others, and if the distance between them is below the user-defined threshold, the images are considered similar and removed from the pool of images to be checked.
-
Users can select from five different hash types:
GradientMeanVertGradientBlockhashDoubleGradient
-
Before hashing, images are typically resized to simplify computations. Supported resizing algorithms:
Lanczos3GaussianCatmullRomTriangleNearest
-
Supported hash sizes:
8x8,16x16,32x32,64x64 -
Both the resizing method and hash size can be adjusted within the application.
Each configuration generates separate cache files to prevent invalid results across different settings.
- Some images may break hash functions, producing hashes filled entirely with
0or255. These images are silently excluded from the final results but remain stored in the cache. - A CLI testing tool is available. To test an algorithm, place a
test.jpgfile in a folder and runczkawka_cli tester -i
The faster comparison option ensures that each pair of results is compared only once, significantly improving performance, especially when using a high similarity threshold.
- Smaller hash size does not always mean faster calculation.
Blockhashis the only algorithm that does not resize images before hashing.- The
Nearestresizing algorithm can be up to five times faster than other methods but may produce worse results. - The
fast_image_resizefeature speeds up image resizing but may slightly reduce accuracy.
This tool works similarly to the Similar Images feature but is designed for video files.
- Requires FFmpeg to function; an error will be displayed if it is not found on the system
- Currently, it only compares videos with almost equal lengths
- Video files are gathered based on their extensions (
.mp4,.mpv,.avi, etc.). - Each file is processed using a hashing algorithm.
- The implementation is handled by an external library, but the process involves:
- Extracting several frames from video
- Generating perceptual hashes for each frame
- The generated hashes are stored in a cache file for future use, reducing redundant calculations
- Using the user-defined similarity tolerance, hashes are compared
- Groups of similar videos are returned as results
This tool detects files that are either corrupted or have an invalid extension.
- Collected are pdf, audio, music and archive files
- If an error occurs while opening a file, it is considered either corrupted(with some exceptions)
- Since tool relies on external libraries, false positives may occur (e.g., this issue), so it is recommended to manually open the file to confirm if it is truly broken
This mode allows finding files whose content does not match their extension.
It works as follows:
- Extracts the current file extension, e.g.,
źrebię.zip→zip - Reads a few bytes from the file
- Matches these bytes with known signatures to determine the likely file type, e.g.,
7z - Retrieves the MIME type (which may return multiple values) based on the detected extension, e.g.,
Mime::Archive - Lists all file extensions associated with this MIME type, e.g.,
rar, 7z, zip, p7 - Expands the list with additional extensions when needed (some files, like
exeanddll, may have similar byte signatures) - If the file's current extension is in the list, it is likely correct; otherwise, it is flagged as having an invalid extension
In the "Proper Extension" column, the extension detected by the Infer library appears in parentheses, while extensions with the same MIME type are displayed outside.

If you want to check code coverage of Czkawka(both in tests or in normal usage) you can execute this simple commands(supports Ubuntu 22.04, but for other OS only installation instruction of packages should be different).
sudo apt install llvm
cargo install rustfilt
RUSTFLAGS="-C instrument-coverage" cargo run --bin czkawka_gui
llvm-profdata merge -sparse default.profraw -o default.profdata
llvm-cov show -Xdemangler=rustfilt target/debug/czkawka_gui -format=html -output-dir=report -instr-profile=default.profdata -ignore-filename-regex="cargo/registry|rustc"
llvm-cov report -Xdemangler=rustfilt target/debug/czkawka_gui --instr-profile=default.profdata -ignore-filename-regex="cargo/registry" > lcov_report.txt
xdg-open report/index.html
xdg-open lcov_report.txt