|
10 | 10 | "\n", |
11 | 11 | "Pre-trained language representations have been shown to improve many downstream NLP tasks such as question answering, and natural language inference. To apply pre-trained representations to these tasks, there are two strategies:\n", |
12 | 12 | "\n", |
13 | | - "feature-based approach, which uses the pre-trained representations as additional features to the downstream task.\n", |
14 | | - "fine-tuning based approach, which trains the downstream tasks by fine-tuning pre-trained parameters.\n", |
15 | | - "While feature-based approaches such as ELMo [3] (introduced in the previous tutorial) are effective in improving many downstream tasks, they require task-specific architectures. Devlin, Jacob, et al proposed BERT [1] (Bidirectional Encoder Representations from Transformers), which fine-tunes deep bidirectional representations on a wide range of tasks with minimal task-specific parameters, and obtained state- of-the-art results.\n", |
| 13 | + " - **feature-based approach**, which uses the pre-trained representations as additional features to the downstream task.\n", |
| 14 | + " - **fine-tuning based approach**, which trains the downstream tasks by fine-tuning pre-trained parameters.\n", |
| 15 | + " \n", |
| 16 | + "While feature-based approaches such as ELMo [1] are effective in improving many downstream tasks, they require task-specific architectures. Devlin, Jacob, et al proposed BERT [2] (Bidirectional Encoder Representations from Transformers), which fine-tunes deep bidirectional representations on a wide range of tasks with minimal task-specific parameters, and obtained state- of-the-art results.\n", |
16 | 17 | "\n", |
17 | 18 | "In this tutorial, we will focus on fine-tuning with the pre-trained BERT model to classify semantically equivalent sentence pairs. Specifically, we will:\n", |
18 | 19 | "\n", |
19 | | - "load the state-of-the-art pre-trained BERT model and attach an additional layer for classification,\n", |
20 | | - "process and transform sentence pair data for the task at hand, and\n", |
21 | | - "fine-tune BERT model for sentence classification.\n", |
| 20 | + " 1. load the state-of-the-art pre-trained BERT model and attach an additional layer for classification\n", |
| 21 | + " 2. process and transform sentence pair data for the task at hand, and \n", |
| 22 | + " 3. fine-tune BERT model for sentence classification.\n", |
22 | 23 | "\n" |
23 | 24 | ] |
24 | 25 | }, |
|
59 | 60 | " [org.apache.clojure-mxnet.callback :as callback]\n", |
60 | 61 | " [org.apache.clojure-mxnet.context :as context]\n", |
61 | 62 | " [org.apache.clojure-mxnet.dtype :as dtype]\n", |
| 63 | + " [org.apache.clojure-mxnet.infer :as infer]\n", |
62 | 64 | " [org.apache.clojure-mxnet.eval-metric :as eval-metric]\n", |
63 | 65 | " [org.apache.clojure-mxnet.io :as mx-io]\n", |
64 | 66 | " [org.apache.clojure-mxnet.layout :as layout]\n", |
|
89 | 91 | "\n", |
90 | 92 | "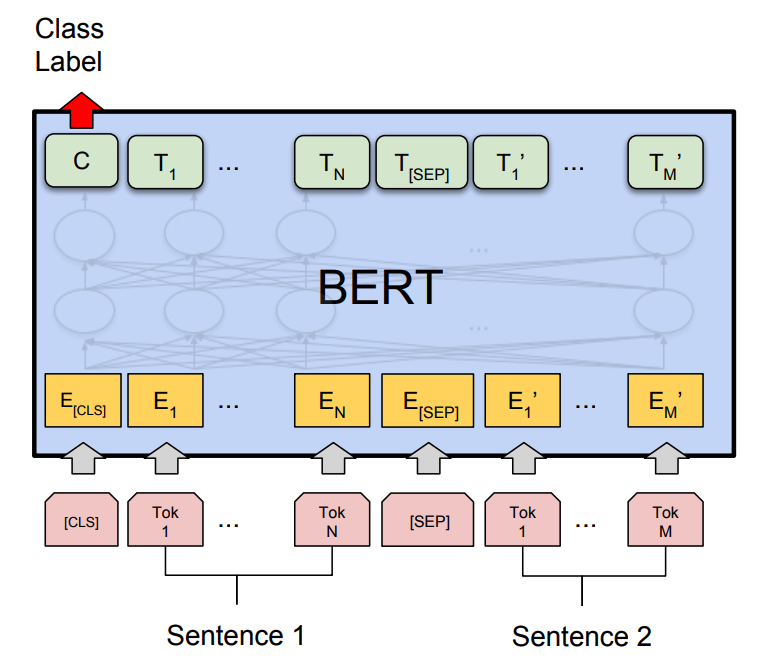\n", |
91 | 93 | "\n", |
92 | | - "where the model takes a pair of sequences and pools the representation of the first token in the sequence. Note that the original BERT model was trained for masked language model and next sentence prediction tasks, which includes layers for language model decoding and classification. These layers will not be used for fine-tuning sentence pair classification.\n", |
| 94 | + "where the model takes a pair of sequences and *pools* the representation of the first token in the sequence. Note that the original BERT model was trained for masked language model and next sentence prediction tasks, which includes layers for language model decoding and classification. These layers will not be used for fine-tuning sentence pair classification.\n", |
93 | 95 | "\n", |
94 | 96 | "Let's load the pre-trained BERT using the module API in MXNet." |
95 | 97 | ] |
|
114 | 116 | ], |
115 | 117 | "source": [ |
116 | 118 | "(def model-path-prefix \"data/static_bert_base_net\")\n", |
| 119 | + "\n", |
117 | 120 | ";; the vocabulary used in the model\n", |
118 | 121 | "(def vocab (bert-util/get-vocab))\n", |
119 | | - ";; the input question\n", |
| 122 | + "\n", |
120 | 123 | ";; the maximum length of the sequence\n", |
121 | 124 | "(def seq-length 128)\n", |
122 | 125 | "\n", |
| 126 | + "(def batch-size 32)\n", |
| 127 | + "\n", |
123 | 128 | "(def bert-base (m/load-checkpoint {:prefix model-path-prefix :epoch 0}))" |
124 | 129 | ] |
125 | 130 | }, |
|
291 | 296 | "source": [ |
292 | 297 | "(defn pre-processing\n", |
293 | 298 | " \"Preprocesses the sentences in the format that BERT is expecting\"\n", |
294 | | - " [ctx idx->token token->idx train-item]\n", |
| 299 | + " [idx->token token->idx train-item]\n", |
295 | 300 | " (let [[sentence-a sentence-b label] train-item\n", |
296 | 301 | " ;;; pre-processing tokenize sentence\n", |
297 | 302 | " token-1 (bert-util/tokenize (string/lower-case sentence-a))\n", |
|
319 | 324 | "(def idx->token (:idx->token vocab))\n", |
320 | 325 | "(def token->idx (:token->idx vocab))\n", |
321 | 326 | "(def dev (context/default-context))\n", |
322 | | - "(def processed-datas (mapv #(pre-processing dev idx->token token->idx %) data-train-raw))\n", |
| 327 | + "(def processed-datas (mapv #(pre-processing idx->token token->idx %) data-train-raw))\n", |
323 | 328 | "(def train-count (count processed-datas))\n", |
324 | 329 | "(println \"Train Count is = \" train-count)\n", |
325 | 330 | "(println \"[PAD] token id = \" (get token->idx \"[PAD]\"))\n", |
|
375 | 380 | " (into []))\n", |
376 | 381 | " :train-num (count processed-datas)})\n", |
377 | 382 | "\n", |
378 | | - "(def batch-size 32)\n", |
379 | | - "\n", |
380 | 383 | "(def train-data\n", |
381 | 384 | " (let [{:keys [data0s data1s data2s labels train-num]} prepared-data\n", |
382 | 385 | " data-desc0 (mx-io/data-desc {:name \"data0\"\n", |
|
480 | 483 | "(def num-epoch 3)\n", |
481 | 484 | "\n", |
482 | 485 | "(def fine-tune-model (m/module model-sym {:contexts [dev]\n", |
483 | | - " :data-names [\"data0\" \"data1\" \"data2\"]}))\n", |
| 486 | + " :data-names [\"data0\" \"data1\" \"data2\"]}))\n", |
484 | 487 | "\n", |
485 | 488 | "(m/fit fine-tune-model {:train-data train-data :num-epoch num-epoch\n", |
486 | 489 | " :fit-params (m/fit-params {:allow-missing true\n", |
|
489 | 492 | " :optimizer (optimizer/adam {:learning-rate 5e-6 :episilon 1e-9})\n", |
490 | 493 | " :batch-end-callback (callback/speedometer batch-size 1)})})\n" |
491 | 494 | ] |
| 495 | + }, |
| 496 | + { |
| 497 | + "cell_type": "markdown", |
| 498 | + "metadata": {}, |
| 499 | + "source": [ |
| 500 | + "### Explore results from the fine-tuned model\n", |
| 501 | + "\n", |
| 502 | + "Now that our model is fitted, we can use it to infer semantic equivalence of arbitrary sentence pairs. Note that for demonstration purpose we skipped the warmup learning rate schedule and validation on dev dataset used in the original implementation. This means that our model's performance will be significantly less than optimal. Please visit [here](https://gluon-nlp.mxnet.io/model_zoo/bert/index.html) for the complete fine-tuning scripts (using Python and GluonNLP).\n", |
| 503 | + "\n", |
| 504 | + "To do inference with our model we need a predictor. It must have a batch size of 1 so we can feed the model a single sentence pair." |
| 505 | + ] |
| 506 | + }, |
| 507 | + { |
| 508 | + "cell_type": "code", |
| 509 | + "execution_count": 14, |
| 510 | + "metadata": {}, |
| 511 | + "outputs": [ |
| 512 | + { |
| 513 | + "data": { |
| 514 | + "text/plain": [ |
| 515 | + "#'bert.bert-sentence-classification/fine-tuned-predictor" |
| 516 | + ] |
| 517 | + }, |
| 518 | + "execution_count": 14, |
| 519 | + "metadata": {}, |
| 520 | + "output_type": "execute_result" |
| 521 | + } |
| 522 | + ], |
| 523 | + "source": [ |
| 524 | + "(def fine-tuned-prefix \"fine-tune-sentence-bert\")\n", |
| 525 | + "\n", |
| 526 | + "(m/save-checkpoint fine-tune-model {:prefix fine-tuned-prefix :epoch 3})\n", |
| 527 | + "\n", |
| 528 | + "(def fine-tuned-predictor\n", |
| 529 | + " (infer/create-predictor (infer/model-factory fine-tuned-prefix\n", |
| 530 | + " [{:name \"data0\" :shape [1 seq-length] :dtype dtype/FLOAT32 :layout layout/NT}\n", |
| 531 | + " {:name \"data1\" :shape [1 seq-length] :dtype dtype/FLOAT32 :layout layout/NT}\n", |
| 532 | + " {:name \"data2\" :shape [1] :dtype dtype/FLOAT32 :layout layout/N}])\n", |
| 533 | + " {:epoch 3}))" |
| 534 | + ] |
| 535 | + }, |
| 536 | + { |
| 537 | + "cell_type": "markdown", |
| 538 | + "metadata": {}, |
| 539 | + "source": [ |
| 540 | + "Now we can write a function that feeds a sentence pair to the fine-tuned model:" |
| 541 | + ] |
| 542 | + }, |
| 543 | + { |
| 544 | + "cell_type": "code", |
| 545 | + "execution_count": 15, |
| 546 | + "metadata": {}, |
| 547 | + "outputs": [ |
| 548 | + { |
| 549 | + "data": { |
| 550 | + "text/plain": [ |
| 551 | + "#'bert.bert-sentence-classification/predict-equivalence" |
| 552 | + ] |
| 553 | + }, |
| 554 | + "execution_count": 15, |
| 555 | + "metadata": {}, |
| 556 | + "output_type": "execute_result" |
| 557 | + } |
| 558 | + ], |
| 559 | + "source": [ |
| 560 | + "(defn predict-equivalence\n", |
| 561 | + " [predictor sentence1 sentence2]\n", |
| 562 | + " (let [vocab (bert.util/get-vocab)\n", |
| 563 | + " processed-test-data (mapv #(pre-processing (:idx->token vocab)\n", |
| 564 | + " (:token->idx vocab) %)\n", |
| 565 | + " [[sentence1 sentence2]])\n", |
| 566 | + " prediction (infer/predict-with-ndarray predictor\n", |
| 567 | + " [(ndarray/array (slice-inputs-data processed-test-data 0) [1 seq-length])\n", |
| 568 | + " (ndarray/array (slice-inputs-data processed-test-data 1) [1 seq-length])\n", |
| 569 | + " (ndarray/array (slice-inputs-data processed-test-data 2) [1])])]\n", |
| 570 | + " (ndarray/->vec (first prediction))))" |
| 571 | + ] |
| 572 | + }, |
| 573 | + { |
| 574 | + "cell_type": "code", |
| 575 | + "execution_count": 22, |
| 576 | + "metadata": {}, |
| 577 | + "outputs": [ |
| 578 | + { |
| 579 | + "data": { |
| 580 | + "text/plain": [ |
| 581 | + "[0.2633881 0.7366119]" |
| 582 | + ] |
| 583 | + }, |
| 584 | + "execution_count": 22, |
| 585 | + "metadata": {}, |
| 586 | + "output_type": "execute_result" |
| 587 | + } |
| 588 | + ], |
| 589 | + "source": [ |
| 590 | + ";; Modify an existing sentence pair to test:\n", |
| 591 | + ";; [\"1\"\n", |
| 592 | + ";; \"69773\"\n", |
| 593 | + ";; \"69792\"\n", |
| 594 | + ";; \"Cisco pared spending to compensate for sluggish sales .\"\n", |
| 595 | + ";; \"In response to sluggish sales , Cisco pared spending .\"]\n", |
| 596 | + "(predict-equivalence fine-tuned-predictor\n", |
| 597 | + " \"The company cut spending to compensate for weak sales .\"\n", |
| 598 | + " \"In response to poor sales results, the company cut spending .\")" |
| 599 | + ] |
| 600 | + }, |
| 601 | + { |
| 602 | + "cell_type": "markdown", |
| 603 | + "metadata": {}, |
| 604 | + "source": [ |
| 605 | + "## References\n", |
| 606 | + "\n", |
| 607 | + "[1] Peters, Matthew E., et al. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018).\n", |
| 608 | + "\n", |
| 609 | + "[2] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018)." |
| 610 | + ] |
492 | 611 | } |
493 | 612 | ], |
494 | 613 | "metadata": { |
|
0 commit comments