散列表类似于数组,可以把散列表的散列值看成数组的索引值。访问散列表和访问数组元素一样快速,它可以在常数时间内实现查找和插入操作。
由于无法通过散列值知道键的大小关系,因此散列表无法实现有序性操作。
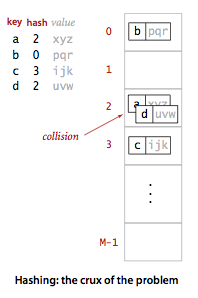
对于一个大小为 M 的散列表,散列函数能够把任意键转换为 [0, M-1] 内的正整数,该正整数即为 hash 值。
散列表存在冲突,也就是两个不同的键可能有相同的 hash 值。
散列函数应该满足以下三个条件:
- 一致性:相等的键应当有相等的 hash 值,两个键相等表示调用 equals() 返回的值相等。
- 高效性:计算应当简便,有必要的话可以把 hash 值缓存起来,在调用 hash 函数时直接返回。
- 均匀性:所有键的 hash 值应当均匀地分布到 [0, M-1] 之间,如果不能满足这个条件,有可能产生很多冲突,从而导致散列表的性能下降。
除留余数法可以将整数散列到 [0, M-1] 之间,例如一个正整数 k,计算 k%M 既可得到一个 [0, M-1] 之间的 hash 值。注意 M 必须是一个素数,否则无法利用键包含的所有信息。例如 M 为 10k,那么只能利用键的后 k 位。
对于其它数,可以将其转换成整数的形式,然后利用除留余数法。例如对于浮点数,可以将其的二进制形式转换成整数。
对于多部分组合的类型,每个部分都需要计算 hash 值,这些 hash 值都具有同等重要的地位。为了达到这个目的,可以将该类型看成 R 进制的整数,每个部分都具有不同的权值。
例如,字符串的散列函数实现如下:
int hash = 0;
for (int i = 0; i < s.length(); i++)
hash = (R * hash + s.charAt(i)) % M;再比如,拥有多个成员的自定义类的哈希函数如下:
int hash = (((day * R + month) % M) * R + year) % M;R 通常取 31。
Java 中的 hashCode() 实现了哈希函数,但是默认使用对象的内存地址值。在使用 hashCode() 时,应当结合除留余数法来使用。因为内存地址是 32 位整数,我们只需要 31 位的非负整数,因此应当屏蔽符号位之后再使用除留余数法。
int hash = (x.hashCode() & 0x7fffffff) % M;使用 Java 的 HashMap 等自带的哈希表实现时,只需要去实现 Key 类型的 hashCode() 函数即可。Java 规定 hashCode() 能够将键均匀分布于所有的 32 位整数,Java 中的 String、Integer 等对象的 hashCode() 都能实现这一点。以下展示了自定义类型如何实现 hashCode():
public class Transaction {
private final String who;
private final Date when;
private final double amount;
public Transaction(String who, Date when, double amount) {
this.who = who;
this.when = when;
this.amount = amount;
}
public int hashCode() {
int hash = 17;
int R = 31;
hash = R * hash + who.hashCode();
hash = R * hash + when.hashCode();
hash = R * hash + ((Double) amount).hashCode();
return hash;
}
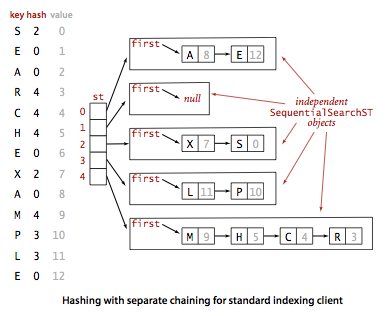
}拉链法使用链表来存储 hash 值相同的键,从而解决冲突。
查找需要分两步,首先查找 Key 所在的链表,然后在链表中顺序查找。
对于 N 个键,M 条链表 (N>M),如果哈希函数能够满足均匀性的条件,每条链表的大小趋向于 N/M,因此未命中的查找和插入操作所需要的比较次数为 ~N/M。
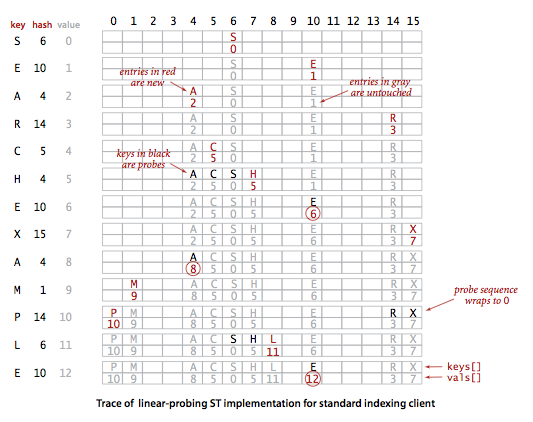
线性探测法使用空位来解决冲突,当冲突发生时,向前探测一个空位来存储冲突的键。
使用线性探测法,数组的大小 M 应当大于键的个数 N(M>N)。
public class LinearProbingHashST<Key, Value> implements UnorderedST<Key, Value> {
private int N = 0;
private int M = 16;
private Key[] keys;
private Value[] values;
public LinearProbingHashST() {
init();
}
public LinearProbingHashST(int M) {
this.M = M;
init();
}
private void init() {
keys = (Key[]) new Object[M];
values = (Value[]) new Object[M];
}
private int hash(Key key) {
return (key.hashCode() & 0x7fffffff) % M;
}
}public Value get(Key key) {
for (int i = hash(key); keys[i] != null; i = (i + 1) % M)
if (keys[i].equals(key))
return values[i];
return null;
}public void put(Key key, Value value) {
resize();
putInternal(key, value);
}
private void putInternal(Key key, Value value) {
int i;
for (i = hash(key); keys[i] != null; i = (i + 1) % M)
if (keys[i].equals(key)) {
values[i] = value;
return;
}
keys[i] = key;
values[i] = value;
N++;
}删除操作应当将右侧所有相邻的键值对重新插入散列表中。
public void delete(Key key) {
int i = hash(key);
while (keys[i] != null && !key.equals(keys[i]))
i = (i + 1) % M;
// 不存在,直接返回
if (keys[i] == null)
return;
keys[i] = null;
values[i] = null;
// 将之后相连的键值对重新插入
i = (i + 1) % M;
while (keys[i] != null) {
Key keyToRedo = keys[i];
Value valToRedo = values[i];
keys[i] = null;
values[i] = null;
N--;
putInternal(keyToRedo, valToRedo);
i = (i + 1) % M;
}
N--;
resize();
}线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时也需要进行很多次探测。例如下图中 2~5 位置就是一个聚簇。
α = N/M,把 α 称为使用率。理论证明,当 α 小于 1/2 时探测的预计次数只在 1.5 到 2.5 之间。为了保证散列表的性能,应当调整数组的大小,使得 α 在 [1/4, 1/2] 之间。
private void resize() {
if (N >= M / 2)
resize(2 * M);
else if (N <= M / 8)
resize(M / 2);
}
private void resize(int cap) {
LinearProbingHashST<Key, Value> t = new LinearProbingHashST<Key, Value>(cap);
for (int i = 0; i < M; i++)
if (keys[i] != null)
t.putInternal(keys[i], values[i]);
keys = t.keys;
values = t.values;
M = t.M;
}